Method to Deal with Memory Corruption in Non-Volatile Device
1. Memory Corruption
1.1. 정의
- 프로그래머의 의도나 프로그래밍 언어의 설계 의도와 달리 메모리 상의 내용이 수정되는 경우를 의미
1.2. 발생 원인
- 환경적 요소
- EMI
- heat
- radiation
- 하드웨어 결함
- power fluctuation
- power failures
- memory cell faults
- address line shorts
- 소프트웨어 결함
- software erroneously modifying memory
1.3. 해결 방법
- H/W적 측면 : UPS나 디커플링 커패시터를 통해 전원 안정화 혹은 MMU / MPU 활용
- S/W적 측면 : BDR(backup and Disaster Recovery) 설계
2. Solution in Software
2.1 CRC 검사를 통한 데이터 무결성 확인
- CRC(cyclic redundancy check) : 데이터 무결성을 확인하는 검사 방식
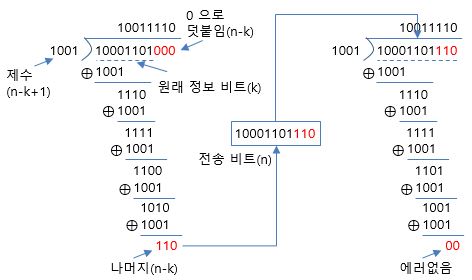
- Data Write : Message + CheckSum(Remainder) bit 붙어서 쓴다.
- Date Read : CheckSum bit가 포함된 Message를 CRC bit로 나누었을 때 0이면 올바른 데이터이며 그렇지 않으면 Memory Corruption이 발생했음을 확인 가능
2.2 Backup block을 통한 Redundancy 보장
Flow Chart

Code
- (1) Main / Backup block 둘다 잘못된 경우
- Default 설정 값 -> Main / Backup block
static ConfigErrorCode proc_in_error(void) { block = configDefault; block.crc = Crc32_calc((const uint8_t *)&block.data, sizeof(ConfigData), 0xffffffff); NVMem_storeData(CONFIG_MAIN_ADDR, sizeof(Config), (const uint8_t *)&block); NVMem_storeData(CONFIG_BACKUP_ADDR, sizeof(Config), (const uint8_t *)&block); return CORRUPT_DATA; }
- Default 설정 값 -> Main / Backup block
- (2) Main block만 잘못된 경우
- Backup block -> Main block
static ConfigErrorCode proc_recovery(void) { block = backupBlock; NVMem_storeData(CONFIG_MAIN_ADDR, sizeof(Config), (const uint8_t *)&block); return RECOVER_DATA; }
- Backup block -> Main block
- (3) Backup block만 잘못된 경우
- Main block -> Backup block
static ConfigErrorCode proc_backup(void) { NVMem_storeData(CONFIG_BACKUP_ADDR, sizeof(Config), (const uint8_t *)&block); return BACKUP_DATA; }
- Main block -> Backup block
- (4) Main block 과 Backup block CRC 설정 값 검사
- 설정 값이 다를 경우, Main block 내용이 가장 최근 내용이므로 Main block으로 값 덮어씀
static ConfigErrorCode proc_cmp(void) { ConfigErrorCode res = NO_ERRORS; if (main.readCRC != backup.readCRC) { res = proc_backup(); } return res; }3. Solution in Hardware
Memory Protection Unit
- 설정 값이 다를 경우, Main block 내용이 가장 최근 내용이므로 Main block으로 값 덮어씀
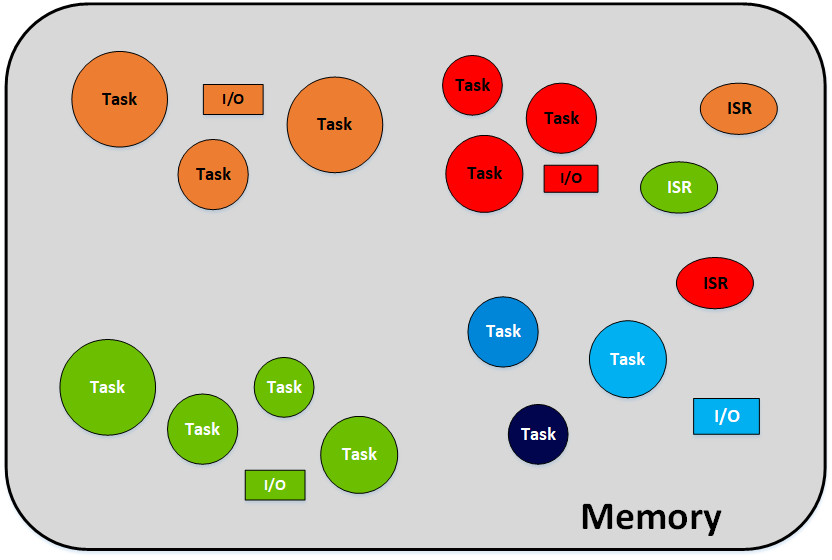
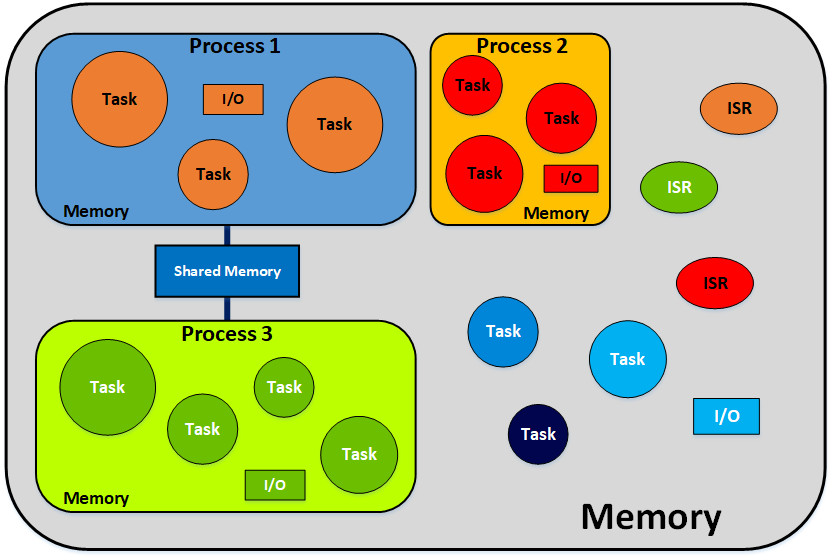
- RTOS에서 Task를 처리하기 위해 필요한 공유 자원들을 효율적으로 관리하기 위해 MPU를 활용한다.
Before Using MPU
After Using MPU
Detecting Stack Overflow using RedZone
- RTOS에서는 Task 마다 고유의 Stack을 가지고 있다.
- Stack으로 인해 RTOS 기반 시스템들은 Stack Overflow 문제를 자주 겪는데, MPU를 통해 이를 해결할 수 있다.
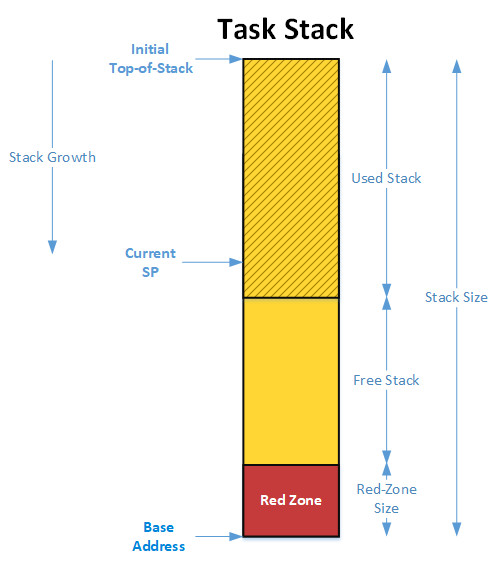
- 다음 MPU Region의 Task Stack으로 부터 Stack Overflow 검출 가능
- Stack Overflow를 검출하기 위해 RedZone이라는 메모리 공간 따로 할당한다.
Alternate way to Detect Stack Overflow

- 각각의 Stack의 크기를 2의 지수배로 똑같은 크기로 설정하면 RedZone을 할당하지 않고서도 Stack Overflow를 검출할 수 있다.
- 이 경우에는 Stack 크기를 일정한 크기로 미리 설정해 두는 것이 복잡한 상황이 될 수 있다.
- 같은 프로세스 내에서 여러 Task를 할당하지 못하게 된다.